Multi-Pod Machine Learning Tasks
One of the beautiful things about a federated data science platform is the ability to run tasks across multiple datasets without needing to centralise the data! Bitfount enables you to train and evaluate models across multiple Pods (this is often referred to as federated learning and evaluation), so your or your partners' data need not be in the same database to collaborate.
There are three quick steps to running ML tasks on multiple Pods:
Let's get you up and running!
Confirming Permissions
Before running multi-Pod tasks, you need to check two items:
- You have the right level of access to all of the Pods you wish to perform tasks against given the task you wish to perform.
- If you intend to use
SecureAggregationas an aggregator for your task, the Pod owners of the Pods you wish to perform tasks against need to allow their Pod(s) to be used in combination with the other Pod(s).
To check whether you have the right level of access for a Pod owned by someone else, go to Accessible Pods in Bitfount Hub, and find the Pod(s) you wish to use. You can see what permission level you have by toggling the "Access Granted" menu:
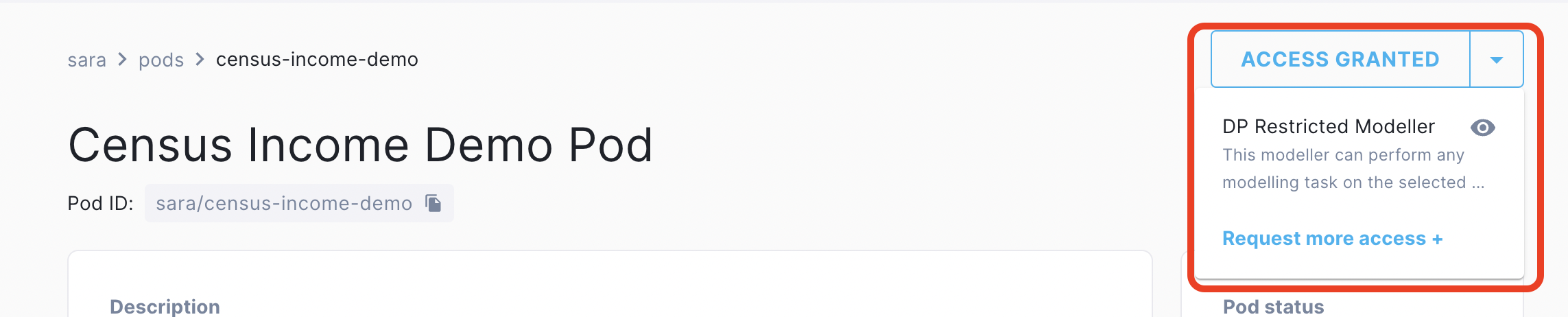
You must have sufficient access across all of the Pods with which you wish to interact to perform a given task. This means your role does not need to be the same across Pods, however, you need to have been assigned a sufficient level of permissions for the task you wish to perform across all of them.
Next, if you wish to use SecureAggregation, the Data Custodians for the desired Pods need to have approved the ability to run ML tasks against the full list of the Pods you wish to use. This includes the case where you are the Pod owner for multiple Pods and wish to query against them. This approval step is performed via the approved_pods parameter using the Bitfount python API or yaml configuration step when creating the Pods. Work with the Data Custodian(s) of the Pods you wish to use to ensure they have included all of the Pods required in the approved_pods list.
Verifying Data Structures
Next, verify that the datasets associated to the Pods you wish to perform tasks against meet the requirements for multi-Pod interaction.
In order to run multi-Pod tasks, the datasets connected to the Pods need to:
Contain the specified columns with the same header names. They do not need to be in the same order across Pods, and the Pods do not have to have the same set of columns. However, the columns you do specify need to have the same header across Pods.
Include the same set of distinct values for fields classified as
categorical. For example, if two Pods both have a "Gender" field, the possible categorical values within the field need to be equivalent across Pods, and there must be at least one example of the values within each dataset. This means if one Pod has "M,F,NB" as values for "Gender", and the other has "M,F,Unspecified" as values, you will not be able to run a task using "Gender" against both Pods. Fields not classified ascategoricaldo not carry this requirement.
Running multi-Pod tasks
Once you've verified your permissions and the data structures, you are ready to run a multi-Pod task!
An example of running a multi-Pod task is explained in detail in tutorial 5. Here is a snippet illustrating a python example of the config required before running the task:
first_pod_identifier = "census-income-demo"
second_pod_identifier = "census-income-yaml-demo"
datastructure = DataStructure(
target="TARGET",
table={
"census-income-demo": "census-income-demo",
"census-income-yaml-demo": "census-income-yaml-demo",
},
)
schema = combine_pod_schemas([first_pod_identifier, second_pod_identifier])
model = PyTorchTabularClassifier(
datastructure=datastructure,
schema=schema,
epochs=2,
batch_size=64,
optimizer=Optimizer(name="SGD", params={"lr": 0.001}),
)
Next Steps
You're now ready to run multi-Pod ML tasks! Still have questions? Check out our Troubleshooting & FAQs guide or reach out to us in the community Slack for help.